
Evaluasi Model

Table of Contents
Pemodelan Regresi Logistik - This article is part of a series.
Setelah melatih model Regresi Logistik, langkah selanjutnya adalah mengevaluasi kinerjanya. Evaluasi model memberikan wawasan tentang seberapa baik model dapat melakukan prediksi pada data yang belum pernah dilihat sebelumnya. Berikut adalah langkah-langkah utama dalam evaluasi model Regresi Logistik:
A. Prediksi dan Probabilitas #
Proses evaluasi melibatkan pembuatan prediksi untuk memahami kelas prediksi yang dihasilkan oleh model, serta memperoleh probabilitas untuk setiap kelas. Pada bagian ini, kita akan menjelaskan proses “Prediksi dan Probabilitas” yang merupakan langkah awal dalam evaluasi model. Prediksi kelas memberikan informasi tentang kategori hasil prediksi (0 atau 1 dalam konteks klasifikasi biner), sementara probabilitas kelas memberikan pemahaman tentang seberapa yakin model terhadap setiap prediksi. Mari kita eksplorasi lebih lanjut langkah-langkah penting dalam mendapatkan prediksi dan probabilitas dari model Regresi Logistik.
1. Prediksi Kelas #
Menggunakan model untuk membuat prediksi pada data pengujian atau data baru. Prediksi ini merupakan kelas yang dihasilkan oleh model (0 atau 1 dalam konteks klasifikasi biner).
predictions = model.predict(X_test)
Fungsi model.predict(X_test) digunakan untuk membuat prediksi kelas pada data yang diberikan (X_test) menggunakan model Regresi Logistik yang telah dilatih. Mari kita bahas lebih detail tentang fungsi ini:
-
model: Merupakan objek model Regresi Logistik yang telah dilatih sebelumnya menggunakan data pelatihan. -
X_test: Matriks atau DataFrame fitur yang digunakan untuk membuat prediksi kelas. Ini adalah data yang belum pernah dilihat oleh model dan digunakan untuk mengukur kinerja model. -
predictions: Hasil dari fungsipredict. Merupakan array atau vektor yang berisi prediksi kelas untuk setiap sampel dalamX_test.
Hasil prediksi kelas ini bersifat biner, di mana nilai 0 mewakili kelas pertama dan nilai 1 mewakili kelas kedua (dalam konteks klasifikasi biner). Fungsi ini memanfaatkan parameter threshold default sebesar 0.5, yang berarti jika probabilitas prediksi lebih besar atau sama dengan 0.5, sampel akan diklasifikasikan ke kelas 1; sebaliknya, jika probabilitas kurang dari 0.5, sampel akan diklasifikasikan ke kelas 0.
Setelah menjalankan fungsi ini, predictions akan berisi prediksi kelas untuk setiap sampel dalam X_test, dan kamu dapat melanjutkan dengan menggunakan berbagai metrik evaluasi untuk mengevaluasi kinerja model tersebut.
2. Probabilitas Kelas #
Pada bagian ini, kita akan membahasa bagaimana memperoleh probabilitas prediksi untuk setiap kelas. Probabilitas ini memberikan perkiraan seberapa yakin model terhadap setiap prediksi.
probabilities = model.predict_proba(X_test)[:, 1]
Fungsi model.predict_proba(X_test) digunakan untuk mendapatkan probabilitas prediksi untuk setiap kelas pada data yang diberikan (X_test) menggunakan model Regresi Logistik yang telah dilatih. Untuk memahami perbedaannya dengan model.predict, mari bahas secara lebih rinci:
probabilities = model.predict_proba(X_test)[:, 1]
-
model: Objek model Regresi Logistik yang telah dilatih sebelumnya menggunakan data pelatihan. -
X_test: Matriks atau DataFrame fitur yang digunakan untuk menghasilkan probabilitas prediksi. Seperti padamodel.predict, ini adalah data yang belum pernah dilihat oleh model. -
probabilities: Hasil dari fungsipredict_proba. Ini adalah matriks yang berisi probabilitas prediksi untuk setiap kelas. Namun, kita hanya memilih kolom kedua ([:, 1]), yang menyimpan probabilitas untuk kelas positif (1).
Perbedaan utama antara model.predict dan model.predict_proba adalah:
-
Output
model.predictmenghasilkan prediksi kelas biner (0 atau 1) berdasarkan threshold default 0.5.model.predict_probamenghasilkan probabilitas untuk setiap kelas, memungkinkan kita untuk melihat sejauh mana model yakin terhadap setiap kelas.
-
Format Output:
- Hasil dari
model.predict_probaberupa matriks dengan dua kolom (khususnya untuk klasifikasi biner). Kolom pertama berisi probabilitas untuk kelas 0 (negatif), dan kolom kedua berisi probabilitas untuk kelas 1 (positif).
- Hasil dari
Jika kita hanya tertarik pada probabilitas untuk kelas positif (1), kita dapat memilih kolom kedua menggunakan [:, 1].
B. Evaluasi Performa #
Evaluasi performa model Regresi Logistik adalah tahap penting setelah pelatihan model. Dalam mengukur kinerja, kita dapat memahami seberapa baik model mampu menggeneralisasi pada data baru dan membuat prediksi yang akurat. Evaluasi performa melibatkan berbagai metrik dan pendekatan yang memberikan wawasan mendalam tentang kekuatan dan kelemahan model.
Pada bagian ini, kita akan mengeksplorasi langkah-langkah yang diperlukan untuk melakukan evaluasi performa yang komprehensif, termasuk akurasi, presisi, recall, dan area di bawah kurva ROC (AUC-ROC). Mari kita tinjau setiap metrik dengan cermat untuk memahami sejauh mana model dapat memenuhi tujuannya dan di mana kita dapat memperbaiki atau menyesuaikan prediksinya. Evaluasi performa adalah jendela yang membuka wawasan mendalam ke dalam kemampuan model Regresi Logistik yang telah dibangun.
1. Akurasi #
Akurasi berfungsi untuk mengukur sejauh mana model dapat memprediksi dengan benar. Akurasi dihitung sebagai rasio prediksi benar terhadap total prediksi.
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, predictions)
Penjelasan:
-
y_test: Merupakan array atau vektor yang berisi label kelas yang sesungguhnya (ground truth) pada dataset pengujian. -
predictions: Merupakan array atau vektor yang berisi prediksi kelas yang dihasilkan oleh model pada dataset pengujian. -
accuracy: Hasil dari fungsi accuracy_score. Nilai ini adalah rasio antara jumlah prediksi yang benar dengan total jumlah prediksi.
Fungsi accuracy_score adalah metrik evaluasi yang digunakan untuk mengukur sejauh mana model klasifikasi memprediksi dengan benar label kelas pada dataset pengujian. Metrik ini memberikan gambaran tentang akurasi keseluruhan dari model, yaitu rasio prediksi yang benar terhadap jumlah total prediksi.
Perlu diperhatikan bahwa y_test dan predictions harus memiliki panjang yang sama. Fungsi ini berguna untuk memberikan gambaran umum tentang seberapa baik model dapat melakukan klasifikasi dengan benar. Meskipun demikian, dalam kasus ketidakseimbangan kelas, akurasi mungkin tidak menjadi metrik evaluasi yang optimal, dan disarankan untuk mempertimbangkan metrik lain seperti presisi, recall, atau area di bawah kurva ROC.
Setelah menjalankan fungsi ini, kita akan mendapatkan nilai akurasi dari model pada dataset pengujian. Semakin tinggi nilai akurasi, semakin baik model dapat memprediksi label kelas pada dataset yang belum pernah dilihat sebelumnya.
2. Presisi dan Recall #
Presisi menunjukkan seberapa banyak prediksi positif yang benar, sedangkan recall mengukur seberapa banyak nilai positif yang berhasil diidentifikasi oleh model.
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, predictions)
recall = recall_score(y_test, predictions)
Fungsi precision_score dan recall_score adalah dua metrik evaluasi yang umum digunakan untuk mengukur kinerja model klasifikasi, termasuk model Regresi Logistik. Mari kita bahas keduanya secara lebih rinci:
a. precision_score (Presisi)
#
Presisi mengukur seberapa banyak dari prediksi positif yang benar. Secara matematis, presisi dihitung sebagai rasio antara true positive (TP) dan jumlah prediksi positif yang dilakukan (TP + false positive atau FP). Formula dari presisi adalah
$$\text{Presisi} = \frac{\text{TP}}{\text{TP} + \text{FP}} $$
from sklearn.metrics import precision_score
precision = precision_score(y_test, predictions)
Penjelasan:
y_test: Merupakan array atau vektor yang berisi label kelas yang sesungguhnya (ground truth) pada dataset pengujian.predictions: Merupakan array atau vektor yang berisi prediksi kelas yang dihasilkan oleh model pada dataset pengujian.precision: Hasil dari fungsi precision_score. Nilai ini berkisar antara 0 dan 1, di mana nilai lebih tinggi menunjukkan tingkat presisi yang lebih baik.
b. recall_score (Recall)
#
Recall, juga dikenal sebagai sensitivitas atau true positive rate, mengukur seberapa banyak dari nilai positif yang berhasil diidentifikasi oleh model. Secara matematis, recall dihitung sebagai rasio antara true positive (TP) dan jumlah nilai positif sebenarnya (TP + false negative atau FN). Formula dari recall adalah
$$\text{Presisi} = \frac{\text{TP}}{\text{TP} + \text{FN}} $$
from sklearn.metrics import recall_score
recall = recall_score(y_test, predictions)
Penjelasan:
y_test: Merupakan array atau vektor yang berisi label kelas yang sesungguhnya (ground truth) pada dataset pengujian.predictions: Merupakan array atau vektor yang berisi prediksi kelas yang dihasilkan oleh model pada dataset pengujian.recall: Hasil dari fungsi recall_score. Nilai ini juga berkisar antara 0 dan 1, di mana nilai lebih tinggi menunjukkan tingkat recall yang lebih baik.
Kedua metrik ini memberikan informasi yang berharga tentang kinerja model dalam mengatasi kelas positif. Presisi memberikan pemahaman tentang sejauh mana model dapat dipercaya ketika memprediksi kelas positif, sedangkan recall memberikan pemahaman tentang sejauh mana model dapat mengidentifikasi semua instance kelas positif yang sebenarnya. Keseimbangan antara presisi dan recall sering menjadi pertimbangan penting tergantung pada konteks dan tujuan bisnis.
3. F1-Score #
F1 Score adalah metrik evaluasi yang menggabungkan presisi (precision) dan recall (sensitivitas) menjadi satu nilai tunggal. Metrik ini berguna ketika kita ingin mencapai keseimbangan antara presisi dan recall, terutama dalam situasi di mana distribusi kelas tidak seimbang.
Formula F1 Score:
$$F1=\frac{2 \times \text{Presisi} \times \text{Recall}}{\text{Presisi} + \text{Recall}}$$
a. Interpretasi F1 Score #
- F1 Score memberikan keseimbangan antara presisi dan recall. Nilai F1 Score berkisar antara 0 dan 1, di mana nilai 1 menunjukkan kinerja yang sempurna.
- F1 Score tinggi menunjukkan bahwa model memiliki presisi dan recall yang baik, sementara F1 Score rendah mungkin terjadi jika salah satu dari presisi atau recall rendah.
b. Kapan Menggunakan F1 Score #
- F1 Score berguna ketika kita ingin mempertimbangkan keseimbangan antara false positives dan false negatives.
- Penting digunakan dalam kasus di mana distribusi kelas target tidak seimbang, dan kita ingin mencegah model menjadi terlalu fokus pada salah satu kelas.
c. Implementasi dalam Python #
from sklearn.metrics import f1_score
# Menghitung F1 Score
f1 = f1_score(y_test, predictions)
Dengan menggunakan F1 Score, kita dapat memiliki metrik evaluasi yang menyeluruh, memberikan gambaran yang baik tentang kemampuan model dalam menangani kelas positif dan kelas negatif secara seimbang.
4. Confusion Matrix #
Confusion Matrix adalah sebuah tabel yang digunakan untuk mengukur kinerja model klasifikasi dengan membandingkan prediksi model terhadap nilai sebenarnya pada dataset pengujian. Confusion Matrix memiliki empat sel atau entri, yang mencerminkan berbagai situasi hasil prediksi. Keempat sel tersebut adalah:
a. True Positive (TP) #
Merupakan situasi di mana model memprediksi dengan benar bahwa sampel merupakan kelas positif (1), dan kenyataannya memang benar positif.
b. False Positive (FP) #
Merupakan situasi di mana model memprediksi secara salah bahwa sampel merupakan kelas positif, tetapi kenyataannya sampel tersebut adalah kelas negatif (0).
c. True Negative (TN) #
Merupakan situasi di mana model memprediksi dengan benar bahwa sampel merupakan kelas negatif, dan kenyataannya memang benar negatif.
d. False Negative (FN) #
Merupakan situasi di mana model memprediksi secara salah bahwa sampel merupakan kelas negatif, tetapi kenyataannya sampel tersebut adalah kelas positif.
Struktur Confusion Matrix:
| Prediksi Positif | Prediksi Negatif |
-----------------|------------------|------------------|
Aktual Positif | TP | FN |
Aktual Negatif | FP | TN |
Dengan struktur tersebut, kita dapat menghitung berbagai metrik evaluasi seperti presisi, recall, akurasi, dan lainnya.
Confusion Matrix memberikan gambaran detil tentang performa model, memungkinkan kita untuk memahami di mana model tersebut berhasil dan di mana terjadi kesalahan. Hal ini sangat penting dalam konteks klasifikasi biner, terutama ketika kelas target memiliki distribusi yang tidak seimbang. Dengan informasi ini, kita dapat membuat keputusan yang lebih informasional dan melakukan penyesuaian pada model jika diperlukan.
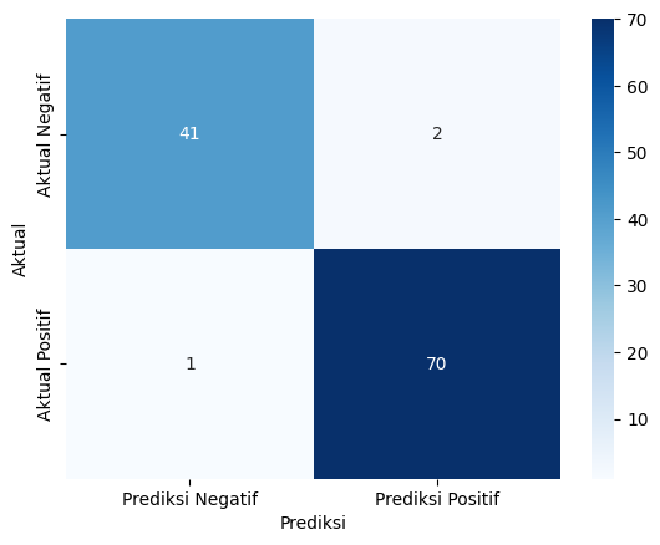
Berikut adalah implementasi confusion matrix pada Python:
from sklearn.metrics import confusion_matrix
# Menghitung Confusion Matrix
cm = confusion_matrix(y_test, predictions)
Berikut adalah visualisasi dari confusion matrix:
C. Kurva Receiver Operating Characteristic (ROC) #
Kurva Receiver Operating Characteristic (ROC) adalah alat evaluasi yang penting dalam mengukur kinerja model klasifikasi biner. Seiring dengan perubahan threshold pengklasifikasian, kurva ROC membantu memahami trade-off antara tingkat True Positive Rate (sensitivitas) dan tingkat False Positive Rate. Pada materi ini, kita akan mengeksplorasi konsep dasar dan implementasi praktis dari kurva ROC, mulai dari pemahaman tentang True Positive Rate (TPR) dan False Positive Rate (FPR) hingga penggunaan fungsi roc_curve dalam scikit-learn untuk menghasilkan dan memvisualisasikan kurva ROC.
Materi ini akan membekali Kamu dengan pemahaman yang mendalam tentang bagaimana menginterpretasikan dan menggunakan kurva ROC untuk meningkatkan kinerja model Regresi Logistik Kamu. Mari kita eksplorasi dunia ROC untuk mendapatkan wawasan lebih lanjut tentang kekuatan dan kelemahan model klasifikasi biner.
1. True Positive Rate (TPR) dan False Positive Rate (FPR) #
True Positive Rate (TPR) dan False Positive Rate (FPR) adalah dua metrik evaluasi yang penting dalam konteks kurva Receiver Operating Characteristic (ROC), terutama untuk model klasifikasi biner. Mari kita bahas keduanya secara lebih rinci:
a. True Positive Rate (TPR) #
- Juga dikenal sebagai sensitivitas atau recall.
- TPR mengukur seberapa baik model dapat mengidentifikasi instances positif sebenarnya dari total instances positif yang ada.
- TPR dihitung sebagai rasio antara True Positive (TP) dan jumlah nilai positif sebenarnya (TP + False Negative atau FN).
- Formula matematis, \(\text{TPR} = \frac{\text{TP}}{\text{TP} + \text{FN}}\).
- TPR memberikan gambaran tentang kemampuan model untuk “menangkap” atau “mengidentifikasi” instances positif sebenarnya.
b. False Positive Rate (FPR) #
- FPR mengukur seberapa sering model salah mengklasifikasikan instances negatif sebenarnya sebagai positif (False Positive).
- FPR dihitung sebagai rasio antara False Positive (FP) dan jumlah nilai negatif sebenarnya (FP + True Negative atau TN).
- Secara matematisnya, \(\text{FPR} = \frac{\text{FP}}{\text{FP} + \text{TN}}\).
- FPR memberikan wawasan tentang seberapa sering model memberikan prediksi positif yang salah terhadap instances yang sebenarnya negatif.
Dalam konteks ROC, kedua metrik ini menjadi penting karena kurva ROC adalah representasi visual dari trade-off antara TPR (di sumbu y) dan FPR (di sumbu x) pada berbagai nilai threshold pengklasifikasian. Semakin mendekati sudut kiri atas kurva ROC, semakin baik kinerja model, karena itu menunjukkan tingkat TPR yang tinggi dan tingkat FPR yang rendah. Keberhasilan model klasifikasi biner sering diukur dengan seberapa baik model dapat mencapai keseimbangan yang baik antara TPR dan FPR, tergantung pada tujuan aplikasi atau kebutuhan bisnis tertentu.
2. Area di Bawah Kurva ROC (AUC-ROC): #
Area di Bawah Kurva ROC berfungsi mengukur kinerja model dengan mempertimbangkan trade-off antara sensitivity dan specificity. Nilai AUC-ROC mendekati 1.0 menunjukkan kinerja yang baik.
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_test, predictions)
Penjelasan:
-
y_test: Merupakan array atau vektor yang berisi label kelas yang sesungguhnya (ground truth) pada dataset pengujian. -
predictions: Merupakan array atau vektor yang berisi probabilitas prediksi untuk kelas positif (1) yang dihasilkan oleh model pada dataset pengujian. -
roc_auc: Hasil dari fungsi roc_auc_score. Nilai ini merupakan area di bawah kurva ROC dan memberikan ukuran tentang seberapa baik model dapat membedakan antara kelas positif dan kelas negatif.
Fungsi roc_auc_score digunakan untuk mengukur kinerja model klasifikasi biner dengan menghitung area di bawah kurva ROC (Receiver Operating Characteristic). Kurva ROC adalah grafik yang mengilustrasikan trade-off antara tingkat true positive (sensitivitas) dan tingkat false positive (1-specificity) pada berbagai threshold pengklasifikasian. Area di bawah kurva ROC (AUC-ROC) menyajikan ukuran singkat sejauh mana model mampu membedakan antara kelas positif dan kelas negatif.
Secara matematis, AUC-ROC dihitung dengan mengukur luas area di bawah kurva ROC. Nilai AUC-ROC berkisar antara 0 hingga 1, di mana nilai 1 menunjukkan kinerja model yang sempurna, dan nilai 0.5 menunjukkan kinerja model yang setara dengan pengklasifikasian acak.
Nilai AUC-ROC yang lebih tinggi menunjukkan bahwa model memiliki kinerja yang lebih baik dalam memisahkan kelas positif dan kelas negatif. Pada umumnya, AUC-ROC di atas 0.8 dianggap sebagai kinerja yang baik, sementara nilai di bawah 0.7 mungkin menunjukkan perlu adanya perbaikan atau penyesuaian pada model.
3. Visualisasi Kurva ROC #
Membuat kurva ROC untuk memvisualisasikan kinerja model pada berbagai threshold. Hal ini membantu pemilihan threshold yang optimal.
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
fpr, tpr, _ = roc_curve(y_test, prediction)
plt.plot(fpr, tpr, label='ROC Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate (Recall)')
plt.legend()
plt.show()
Berikut adalah hasilnya:

Fungsi roc_curve digunakan untuk menghitung nilai True Positive Rate (TPR), False Positive Rate (FPR), dan threshold yang terkait untuk berbagai threshold yang mungkin dalam pengklasifikasian biner. Hasilnya dapat digunakan untuk membuat kurva karakteristik operasi penerima (ROC).
Kurva ROC adalah grafik yang membantu mengukur kinerja model klasifikasi biner di berbagai threshold. Semakin mendekati sudut kiri atas, semakin baik kinerja model. Fungsi roc_curve menyediakan informasi yang berguna untuk membentuk kurva ROC dan memilih threshold yang sesuai dengan kebutuhan spesifik Kamu.
Evaluasi model Regresi Logistik melibatkan serangkaian metrik dan visualisasi yang memberikan pemahaman holistik tentang kemampuan model dalam melakukan prediksi. Akurasi, presisi, recall, dan kurva ROC adalah alat yang berguna untuk mengevaluasi kinerja model dari berbagai perspektif.