

Pemahaman Data Time Series

Table of Contents
Pandas - Proses Data Time Series - This article is part of a series.
Setelah kita menyiapkan lingkungan pengembangan (development environment) dan memasukkan dataset penjualan, langkah berikutnya adalah memahami data time series yang kita miliki. Dalam konteks dataset yang digunakan (data_penjualan.csv), kita akan menganalisa informasi yang terkandung dalam dataset tersebut.
A. Pengenalan Dataset “Data Penjualan” #
Dataset ini mencakup informasi penjualan dengan tiga kolom utama:
- Tanggal: Menunjukkan tanggal transaksi.
- Kategori: Merupakan kategori produk, seperti “Elektronik”, “Pakaian”, atau “Buku”.
- Jumlah: Menunjukkan jumlah barang yang terjual pada tanggal dan kategori tertentu.
B. Persiapan Dataset #
Sebelum kita mulai analisis, pertama-tama kita perlu melihat bagaimana dataset ini terstruktur dan apakah ada perubahan atau penyesuaian yang perlu dilakukan. Kita akan mengecek beberapa baris pertama dataset untuk mendapatkan gambaran awal:
# Menampilkan 5 data pertama dari dataset penjualan
print("5 Data Pertama dari Dataset Penjualan:")
print(sales_data.head())
Hasilnya
5 Data Pertama dari Dataset Penjualan:
Unnamed: 0 Tanggal Kategori Jumlah
0 0 2022-01-01 Elektronik 9.0
1 1 2022-01-02 Elektronik 4.0
2 2 2022-01-02 Pakaian 8.0
3 3 2022-01-02 Buku 4.0
4 4 2022-01-03 Pakaian 7.0
B. Handling Missing Values #
Dalam proses analisis data time series, seringkali kita dihadapkan dengan nilai yang hilang. Pandas menyediakan berbagai metode untuk menangani nilai yang hilang pada data time series.
1. Pemeriksaan dan Pengelolaan Missing Values #
Pemeriksaan nilai yang hilang dapat dilakukan dengan menggunakan fungsi isnull() pada DataFrame.
Pengelolaan nilai yang hilang dapat melibatkan penghapusan baris atau kolom yang mengandung nilai yang hilang atau mengisi nilai yang hilang dengan nilai tertentu.
sales_data[sales_data.isnull().any(axis=1)]
Berikut adalah hasilnya
Unnamed: 0 Tanggal Kategori Jumlah
218 218 2022-05-25 Pakaian NaN
219 219 2022-05-26 Elektronik NaN
222 222 2022-05-27 Buku NaN
395 395 2022-09-19 Pakaian NaN
399 399 2022-09-22 Elektronik NaN
403 403 2022-09-23 Buku NaN
Terlihat bahwa terdapat beberapa baris dengan data yang hilang pada kolom Jumlah. Kita dapat menghitung jumalh baris di atas dengan cepat menggunakan sum().
# Contoh: Pemeriksaan dan pengelolaan nilai yang hilang
sales_data.isnull().sum() # Menampilkan jumlah nilai yang hilang untuk setiap kolom
Hasilnya:
Unnamed: 0 0
Kategori 0
Jumlah 6
dtype: int64
Terlihat bahwa terdapat 6 data dengan kolom Jumlah yang hilang. Terdapat 3 pilihan untuk menangani missim values, yaitu menghapus data yang mengandung missing values, mengganti nilai yang hilang dengan nilai rata-rata atau menggunakan interpolasi untuk mengisi nilai yang hilang. Kita akan menghapus data yang mengandung missing values.
2. Menghapus Data yang Mengandung Missing Values #
Untuk menghapus data yang mengandung missing values, gunakan perintah berikut:
sales_data.dropna(inplace=True) # Menghapus baris yang mengandung nilai yang hilang
C. Inspeksi Awal Data #
Setelah menangani data yang hilang, kita dapat melihat struktur umum dataset dan memahami cara informasi waktu direpresentasikan. Selanjutnya, kita akan menjalankan beberapa fungsi untuk mendapatkan pemahaman yang lebih mendalam:
1. Statistik Deskriptif #
Setelah melihat beberapa data pertama, kita ingin mendapatkan pemahaman statistik deskriptif dari dataset tersebut. Informasi ini melibatkan rata-rata, median, kuartil, dan deviasi standar.
# Deskripsi statistik deskriptif untuk dataset penjualan
print("Statistik Deskriptif untuk Dataset Penjualan:")
print(sales_data['Jumlah'].describe())
Outputnya akan memberikan gambaran umum tentang sebaran nilai dalam dataset, membantu kita mengidentifikasi kecenderungan dan variabilitas.
Berikut adalah outputnya:
Statistik Deskriptif untuk Dataset Penjualan:
count 1105.000000
mean 6.310407
std 4.301850
min 1.000000
25% 3.000000
50% 6.000000
75% 9.000000
max 30.000000
Name: Jumlah, dtype: float64
Berikut adalah analisa dari statistik di atas:
-
Count (Jumlah Observasi):
Jumlah observasi atau entri dalam dataset penjualan adalah 1105. Ini menunjukkan bahwa kita memiliki data untuk 1105 periode waktu atau transaksi penjualan.
-
Mean (Rata-rata):
Rata-rata penjualan per periode waktu adalah sekitar 6.310407. Ini memberikan gambaran nilai tengah dari distribusi penjualan.
-
Std (Deviasi Standar):
Standar deviasi penjualan sekitar 4.301850. Nilai ini mengindikasikan sejauh mana penjualan bervariasi dari rata-ratanya. Semakin tinggi deviasi standar, semakin besar variabilitasnya.
-
Min (Nilai Minimum):
Nilai minimum penjualan dalam satu periode waktu adalah 1. Ini menunjukkan bahwa ada periode waktu di mana penjualan sangat rendah, mungkin mencerminkan adanya periode penurunan aktivitas penjualan.
-
25% (Kuartil Pertama):
Kuartil pertama atau 25% dari data memiliki nilai penjualan sekitar 3. Ini memberikan informasi tentang sebaran data pada bagian bawah distribusi.
-
50% (Median atau Kuartil Kedua):
Median penjualan, yang juga merupakan nilai tengah, adalah 6. Setengah dari data memiliki nilai penjualan di bawah 6, dan setengahnya lagi di atas 6.
-
75% (Kuartil Ketiga):
Kuartil ketiga atau 75% dari data memiliki nilai penjualan sekitar 9. Ini memberikan informasi tentang sebaran data pada bagian atas distribusi.
-
Max (Nilai Maksimum):
Nilai maksimum penjualan dalam satu periode waktu adalah 30. Ini mencerminkan titik tertinggi dari distribusi penjualan, menunjukkan adanya periode dengan aktivitas penjualan yang tinggi.
Kesimpulan:
- Statistik deskriptif memberikan gambaran umum tentang distribusi data penjualan.
- Rata-rata penjualan yang relatif stabil di sekitar 6.31, dengan variabilitas sekitar 4.3.
- Distribusi penjualan cenderung terpusat di sekitar nilai median 6, dengan rentang nilai antara 1 hingga 30.
Dengan menganalisis statistik deskriptif, kita dapat memahami karakteristik umum dari dataset penjualan ini.
2. Visualisasi Awal #
Selanjutnya, kita akan membuat visualisasi awal untuk mendapatkan wawasan tentang pola atau tren yang mungkin ada dalam data time series. Dalam contoh ini, kita akan menggunakan plot garis untuk melihat bagaimana rata-rata penjualan per bulan berubah seiring waktu.
import pandas as pd
import matplotlib.pyplot as plt
# Visualisasi rata-rata penjualan per bulan per kategori
average_penjualan_per_bulan = sales_data.groupby([sales_data.index.to_period('M'), 'Kategori'])['Jumlah'].mean().unstack()
plt.figure(figsize=(12, 6))
average_penjualan_per_bulan.plot(kind='line', marker='o', linestyle='-')
plt.title('Rata-rata Penjualan per Bulan per Kategori')
plt.xlabel('Bulan')
plt.ylabel('Rata-rata Penjualan')
plt.legend(title='Kategori', loc='upper right')
plt.grid(True)
plt.show()
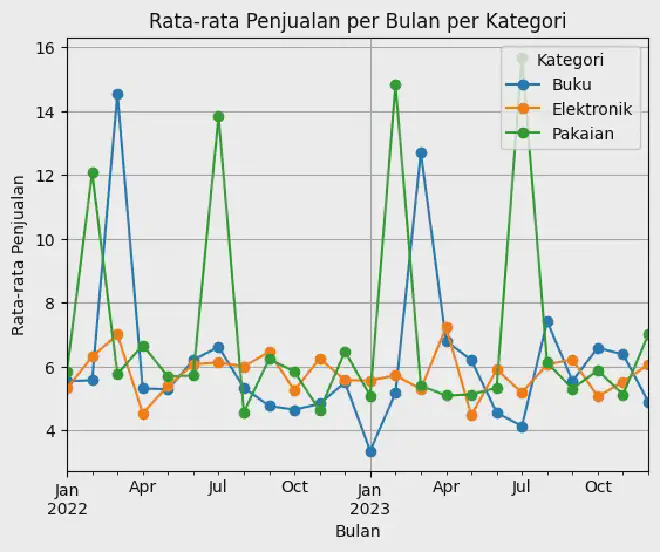
Grafik tersebut akan memberikan gambaran visual tentang pola penjualan dan apakah terdapat tren atau pola musiman tertentu.
-
Kategori “Buku”
- Menunjukkan fluktuasi penjualan yang cukup signifikan, dengan puncak penjualan pada Maret 2022, tetapi mengalami penurunan setelahnya.
- Terlihat beberapa kenaikan penjualan pada Oktober 2022 dan September 2023.
- Penjualan relatif stabil pada awal 2023.
-
Kategori “Elektronik”
- Memiliki tingkat penjualan yang tinggi secara keseluruhan, dengan beberapa bulan (Februari dan Maret 2022, serta Juli 2023) mencapai puncak penjualan tertinggi.
- Terlihat fluktuasi penjualan yang signifikan, terutama pada Februari 2023.
- Pada bulan-bulan tertentu, penjualan “Elektronik” jauh melebihi penjualan kategori lainnya.
-
Kategori “Pakaian”
- Menunjukkan fluktuasi yang cukup besar, terutama pada bulan-bulan Juli (2022 dan 2023) di mana terjadi lonjakan penjualan yang signifikan.
- Pada beberapa bulan, penjualan “Pakaian” sangat tinggi, sementara pada bulan lainnya cenderung lebih rendah.
Dari analisa tersebut dapat disimpulkan beberapa hal berikut:
- Musim atau Tren Mode
Kategori “Pakaian” mungkin lebih dipengaruhi oleh tren mode dan perubahan musim, sehingga fluktuasi penjualan yang signifikan terjadi pada bulan-bulan tertentu.
- Perangkat Elektronik
Kategori “Elektronik” mungkin lebih terpengaruh oleh siklus produk, dengan perilisan atau pembaruan produk tertentu yang meningkatkan minat dan penjualan.
- Buku Sebagai Konsumsi Rutin
Penjualan buku mungkin lebih terkait dengan kebiasaan konsumsi rutin, dan fluktuasi mungkin lebih dipengaruhi oleh peristiwa umum atau promosi khusus. Perbandingan ini memberikan pandangan yang lebih mendalam tentang performa relatif masing-masing kategori.
Dengan melakukan inspeksi awal ini, kita dapat memahami struktur dataset penjualan, melihat distribusi statistik deskriptif, dan mendapatkan wawasan awal tentang pola waktu yang mungkin ada dalam data. Langkah selanjutnya adalah melanjutkan analisis lebih lanjut berdasarkan temuan dari inspeksi ini.