Pengolahan Data Time Series dengan Pandas

Table of Contents
Pandas - Proses Data Time Series - This article is part of a series.
A. Handling Data Time Series #
1. Convert Kolom Tanggal ke DateTime
#
Ketika bekerja dengan data time series menggunakan Pandas, sangat penting untuk mengonversi kolom yang berisi informasi tanggal menjadi tipe data DateTime. Hal ini memungkinkan kita untuk memanfaatkan berbagai fungsi dan metode khusus yang disediakan oleh Pandas untuk manipulasi dan analisis data waktu.
# Contoh: Mengonversi kolom 'Tanggal' menjadi tipe data DateTime
sales_data['Tanggal'] = pd.to_datetime(sales_data['Tanggal'])
Dengan mengonversi kolom ‘Tanggal’ menjadi DateTime, kita dapat dengan mudah melakukan operasi seperti pemotongan waktu, perbandingan tanggal, dan pengelompokan berdasarkan interval waktu tertentu.
2. Pentingnya Index pada Kolom Tanggal #
Selain mengonversi kolom ‘Tanggal’ menjadi DateTime, penting juga untuk menjadikannya sebagai indeks DataFrame. Menjadikan kolom ‘Tanggal’ sebagai indeks memberikan beberapa keuntungan:
-
Akses Cepat: Memudahkan akses dan pencarian data berdasarkan tanggal tanpa harus melakukan pemindaian seluruh dataset.
-
Pemotongan Waktu: Menyederhanakan operasi pemotongan waktu, seperti pengambilan data dalam rentang waktu tertentu.
-
Fungsi Time-Based: Memungkinkan penggunaan fungsi-fungsi khusus time series Pandas, seperti resampling dan rolling windows.
# Contoh: Menjadikan kolom 'Tanggal' sebagai indeks DataFrame
sales_data.set_index('Tanggal', inplace=True)
Dengan menjadikan kolom ‘Tanggal’ sebagai indeks, kita dapat memanfaatkan kemudahan dan efisiensi dalam melakukan analisis dan visualisasi data time series.
B. Resampling Data #
Resampling data time series adalah teknik untuk mengubah frekuensi data menjadi frekuensi yang lebih rendah atau lebih tinggi. Tujuannya bervariasi tergantung pada kebutuhan analisis atau model yang akan dilakukan.
1. Downsampling #
Resampling dapat digunakan untuk merubah frekuensi data. Downsample dapat dilakukan dengan mengurangi frekuensi data, misalnya, merubah data harian menjadi mingguan.
# Contoh: Downsample data harian menjadi mingguan
weekly_sales = sales_data['Jumlah'].resample('W').sum()
Berikut adalah plot data weekly_sales

Motivasi utama melakukan downsampling adalah untuk mengubah frekuensi data menjadi lebih rendah. Penurunan frekuensi dapat membantu dalam analisis data yang lebih luas, terutama jika data awal memiliki tingkat frekuensi yang tinggi.
Diantara tujuan dari downsampling adalah menyederhanakan data yang memiliki frekuensi tinggi sehingga lebih mudah dipahami. Selain itu, downsampling berfungsi untuk mengurangi jumlah data, yang dapat berguna jika analisis dilakukan pada rentang waktu yang lebih besar.
Pada contoh di atas, kita menggunakan fungsi aggregasi sum. Kamu bisa juga menggunakan fungsi aggregasi data yang lain seperti mean atau yang lainnya menyesuaikan kebutuhan.
Contoh Aplikasi:
Jika kita memiliki data penjualan harian dan ingin melihat tren penjualan mingguan, melakukan downsampling dapat memberikan gambaran yang lebih jelas dan mengurangi kebisingan harian.
2. Upsampling #
Upsample meningkatkan frekuensi data, seperti merubah data bulanan menjadi harian. Metode pengisian (filling) sering digunakan untuk mengisi nilai yang hilang.
# Contoh: Upsample data bulanan menjadi harian dengan mengisi nilai-nilai yang hilang
daily_sales = sales_data['Jumlah'].resample('D').ffill()
Motivasi utama melakukan upsampling adalah untuk meningkatkan frekuensi data menjadi lebih tinggi. Diperlukan ketika analisis memerlukan detail yang lebih tinggi dari data yang tersedia.
C. Pengelompokan Waktu (Time-based Grouping) #
1. Grouping Berdasarkan Tahun, Bulan, atau Hari: #
Mengelompokkan data time series berdasarkan periode tertentu dapat memberikan pemahaman yang lebih baik tentang tren dan pola data.
# Contoh: Mengelompokkan penjualan berdasarkan tahun dan bulan
monthly_grouped_sales = sales_data.groupby([sales_data.index.year, sales_data.index.month])['Jumlah'].sum()
Penjelasan:
sales_data.groupby([sales_data.index.year, sales_data.index.month]): Ini adalah bagian yang melakukan pengelompokan data. Kita menggunakan fungsi groupby pada objek DataFrame (sales_data), dan sebagai kunci pengelompokan, kita menggunakan tahun (sales_data.index.year) dan bulan (sales_data.index.month). Ini akan menghasilkan grup-grup berdasarkan kombinasi tahun dan bulan.
2. Operasi Agregasi pada Grup #
Setelah pengelompokan, operasi agregasi seperti sum, mean, atau count dapat dilakukan untuk mendapatkan ringkasan data.
# Contoh: Menghitung rata-rata penjualan bulanan
average_monthly_sales = monthly_grouped_sales.mean()
Hasilnya adalah sebagai berikut:
Tanggal Bulan
2023 1 4.206897
2 4.269231
3 4.966667
4 4.827586
5 4.903226
6 5.366667
7 5.193548
8 5.548387
9 5.566667
10 5.548387
11 5.266667
12 6.096774
Name: Jumlah, dtype: float64
Dengan memahami penggunaan DateTime dan teknik resampling serta pengelompokan waktu, kita dapat menjalankan analisis yang lebih mendalam terhadap data time series dalam Pandas.
D. Menggunakan Rolling Windows #
Penggunaan jendela geser (rolling windows) adalah untuk menghitung statistik pada bagian tertentu dari data time series. Tujuannya utamanya adalah untuk melihat tren dan pola jangka pendek dalam data serta memberikan pandangan yang lebih halus terhadap variasi.
Fungsi rolling() pada Pandas digunakan untuk menerapkan operasi jendela geser (rolling window) ke data time series. Fungsi ini memungkinkan kita untuk menghitung statistik atau menerapkan fungsi aggregasi pada setiap jendela data yang bergerak sepanjang deret waktu. Berikut adalah format umum penggunaan fungsi rolling():
# Format Penggunaan Fungsi Rolling pada Pandas
data_series.rolling(window=window_size, min_periods=min_periods).operation()
# Keterangan:
# - data_series: Pandas Series yang merupakan data time series.
# - window_size: Ukuran jendela geser, menentukan berapa banyak titik data yang akan diikutsertakan dalam perhitungan.
# - min_periods: Jumlah minimum periode yang diperlukan untuk menghasilkan output yang tidak berupa NaN.
# - operation(): Operasi atau fungsi aggregasi yang akan diterapkan pada setiap jendela geser.
Contoh Penggunaan Fungsi Rolling:
# Menggunakan rolling window untuk rata-rata bergerak selama 7 hari
rolling_average = sales_data['Jumlah'].rolling(window=7).mean()
Penjelasan Kode:
sales_data['Jumlah']: Ini adalah kolom penjualan dari data time series..rolling(window=7): Menghasilkan objek bergulir dengan jendela bergulir selama 7 hari..mean(): Menghitung rata-rata bergerak selama jendela bergulir.
Hasil dari contoh di atas adalah:
Tanggal
2023-01-01 NaN
2023-01-02 NaN
2023-01-03 NaN
2023-01-04 NaN
2023-01-05 NaN
...
2023-12-27 6.285714
2023-12-28 6.285714
2023-12-29 7.142857
2023-12-30 7.428571
2023-12-31 7.142857
Name: Jumlah, Length: 359, dtype: float64
Penting untuk dicatat bahwa kita dapat mengganti mean() dengan fungsi aggregasi atau operasi lainnya seperti sum(), min(), max(), atau menggunakan fungsi kustom sesuai kebutuhan analisis kita. Parameter tambahan seperti min_periods dapat digunakan untuk menangani nilai yang hilang dengan memberikan jumlah minimum periode yang diperlukan untuk menghasilkan output yang valid.
E. Differencing #
Differencing adalah metode untuk menghilangkan tren atau pola periodik dalam data dengan mengurangkan nilai pada waktu tertentu dengan nilai pada waktu sebelumnya. Pandas menyediakan fungsi diff untuk melakukan differencing.
Fungsi diff() pada Pandas digunakan untuk menghitung perbedaan antara satu elemen dengan elemen sebelumnya dalam Pandas Series atau DataFrame. Ini adalah teknik differencing yang berguna dalam membuat data menjadi stasioner dengan menghilangkan tren atau pola periodik. Berikut adalah format umum penggunaan fungsi diff():
# Format Penggunaan Fungsi Diff pada Pandas
data_series.diff(periods=periods, axis=axis)
Keterangan:
data_series: Pandas Series atau DataFrame yang ingin dihitung perbedaannya. periods: Jumlah langkah ke belakang untuk menghitung perbedaan. Jika tidak disebutkan, defaultnya adalah 1.axis: Penunjuk sumbu yang ingin dihitung perbedaannya (0 untuk baris, 1 untuk kolom). Hanya berlaku jika digunakan pada DataFrame.
Contoh Penggunaan:
Pada data penjualan ingin menghilangkan tren harian untuk memfokuskan analisis pada fluktuasi harian yang lebih kecil.
# Melakukan differencing untuk menghilangkan tren
differenced_data = sales_data['Jumlah'].diff()
Hasil dari contoh di atas adalah:
Tanggal
2023-01-01 NaN
2023-01-02 -2.0
2023-01-03 -2.0
2023-01-04 6.0
2023-01-05 -2.0
...
2023-12-27 2.0
2023-12-28 -2.0
2023-12-29 2.0
2023-12-30 1.0
2023-12-31 -4.0
Name: Jumlah, Length: 359, dtype: float64
Dalam contoh ini, kita menggunakan fungsi diff() untuk menghitung selisih antara setiap nilai dengan nilai sebelumnya. Hasilnya adalah time series baru yang mencerminkan perubahan harian dalam kualitas udara.
Penting untuk dicatat bahwa hasil differencing akan menghasilkan nilai NaN pada elemen pertama karena tidak ada elemen sebelumnya untuk dihitung perbedaannya. Jika diperlukan, kita dapat menggunakan parameter periods untuk menyesuaikan jumlah langkah ke belakang yang diinginkan.
1. Penanganan Missing Values setelah Differencing #
Setelah differencing, mungkin terdapat nilai yang hilang. Penting untuk menangani nilai-nilai tersebut dengan benar sebelum melanjutkan analisis.
# Menangani nilai yang hilang setelah differencing
differenced_data.dropna(inplace=True)
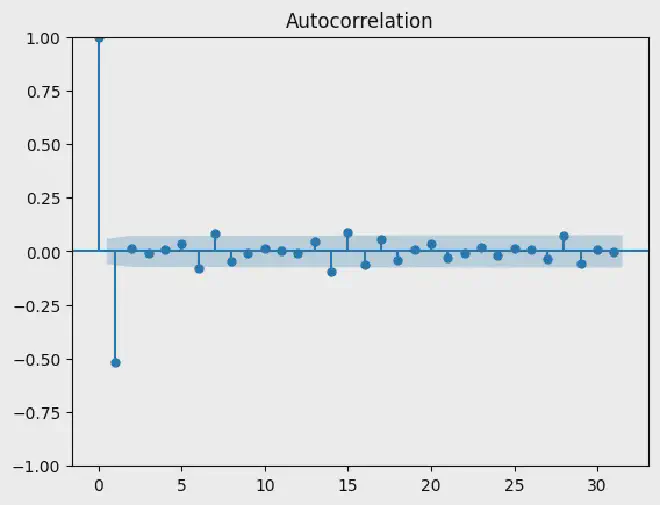
2. Menggunakan Differencing dalam Analisis #
Differencing sering digunakan untuk mengidentifikasi pola musiman, mengurangi dampak tren jangka panjang, dan meningkatkan interpretasi analisis statistik seperti autokorelasi.
# Melihat plot ACF (Autocorrelation Function) setelah differencing
from statsmodels.graphics.tsaplots import plot_acf
# Plot ACF setelah differencing
plot_acf(differenced_data.dropna())
Hasil adalah: