

Pengelolaan Data yang Imbalance

Table of Contents
Persiapan Data untuk Machine Learning - This article is part of a series.
A. Mengenal Data yang Imbalance (Tidak Seimbang) #
Dataset dengan ketidakseimbangan kelas adalah dataset di mana sebuah kelas memiliki frekuensi yang jauh lebih tinggi atau lebih rendah dibandingkan kelas lain. Ketidakseimbangan kelas dapat menyebabkan model machine learning cenderung mengabaikan kelas minoritas. Hal ini dapat berdampak negatif pada kemampuan model untuk mengenali dan memprediksi kelas yang kurang umum.
Mengelola data yang tidak seimbang bertujuan untuk meningkatkan performa model pada kelas minoritas. Beberapa langkah yang dapat diambil termasuk oversampling (menambahkan lebih banyak contoh dari kelas minoritas) atau undersampling (mengurangi jumlah contoh dari kelas mayoritas).
Berikut ini kita akan melihat sebaran kelas pada dataset “UCI ML Breast Cancer Wisconsin”.
import matplotlib.pyplot as plt
import numpy as np
# Hitung frekuensi setiap kelas
unique_classes, class_counts = np.unique(y, return_counts=True)
# Plot diagram batang
plt.bar(unique_classes, class_counts, color=['blue', 'orange'])
plt.xlabel('Kelas')
plt.ylabel('Frekuensi')
plt.title('Distribusi Kelas')
plt.xticks(unique_classes, ['malignant', 'benign'])
plt.show()
Berikut adalah hasilnya:
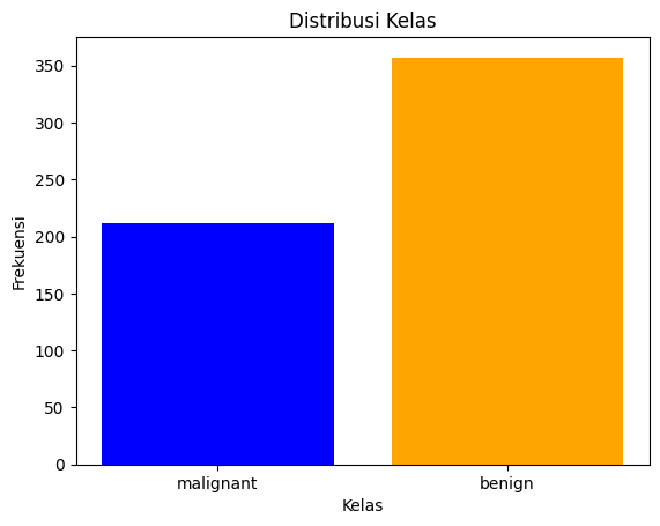
Terlihat bahwa jumlah kelas benign (jinak) lebih banyak daripada kelas malignant (ganas). Hal ini menunjukan contoh ketidakseimbangan data.
B. Oversampling dengan SMOTE (Synthetic Minority Over-sampling Technique) #
1. Mengenal SMOTE #
SMOTE (*Synthetic Minority Over-sampling Technique), adalah salah satu metode oversampling yang digunakan dalam pemrosesan data untuk menangani ketidakseimbangan kelas. Oversampling bertujuan untuk meningkatkan jumlah contoh dalam kelas minoritas (kelas yang kurang banyak contohnya) untuk meminimalkan dampak ketidakseimbangan kelas pada model pembelajaran mesin.
2. Prinsip Dasar SMOTE #
Berikut adalah penjelasan lebih detail tentang SMOTE:
- SMOTE bekerja dengan membuat data sampel sintetis baru dalam ruang fitur antara sampel-sampel yang sudah ada dalam kelas minoritas.
- Untuk setiap data sampel dalam kelas minoritas, SMOTE memilih beberapa tetangga terdekat (biasanya \(K\) tetangga terdekat, di mana \(K\) adalah parameter yang dapat diatur).
- SMOTE kemudian membuat data sampel sintetis baru di sepanjang garis yang menghubungkan sampel tersebut dengan beberapa tetangganya.
3. Algoritma SMOTE #
- Pilih satu data sampel secara acak dari kelas minoritas.
- Cari \(K\) tetangga terdekat untuk sampel tersebut.
- Pilih salah satu tetangga dan hitung perbedaan antara fitur sampel tersebut dengan fitur tetangga tersebut.
- Kalikan perbedaan tersebut dengan suatu angka acak (umumnya antara 0 dan 1) dan tambahkan hasilnya ke fitur sampel tadi.
- Ulangi langkah tersebut hingga jumlah data sampel sintetis yang diinginkan telah dibuat.
4. Kelebihan dan Kekurangan SMOTE #
Berikut adalah beberapa kelebihan dari metode SMOTE:
- Mengatasi masalah ketidakseimbangan kelas.
- Meningkatkan kinerja model pada kelas minoritas.
Berikut adalah kekurangan dari metode SMOTE:
- SMOTE dapat membuat beberapa data sampel sintetis yang tidak realistis jika tidak digunakan dengan hati-hati.
- Pemilihan parameter seperti jumlah tetangga (\(K\)) dapat mempengaruhi hasil dari SMOTE.
5. Implementasi SMOTE #
SMOTE dapat diimplementasikan dengan menggunakan library seperti scikit-learn di Python (from imblearn.over_sampling import SMOTE).
Contoh penggunaan SMOTE dalam Python dengan scikit-learn:
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# Split dataset menjadi train dan test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Menggunakan SMOTE untuk oversampling
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
X_resampled dan y_resampled adalah versi data pelatihan yang telah di-oversampling untuk menciptakan keseimbangan antara kelas.
Setelah itu, kita coba lihat kembali distribusi kelas setelah proses oversampling di atas.
import matplotlib.pyplot as plt
import numpy as np
# Hitung frekuensi setiap kelas
unique_classes, class_counts = np.unique(y_resampled, return_counts=True)
# Plot diagram batang
plt.bar(unique_classes, class_counts, color=['blue', 'orange'])
plt.xlabel('Kelas')
plt.ylabel('Frekuensi')
plt.title('Distribusi Kelas')
plt.xticks(unique_classes, ['malignant', 'benign'])
plt.show()
Hasilnya adalah sebagai berikut:
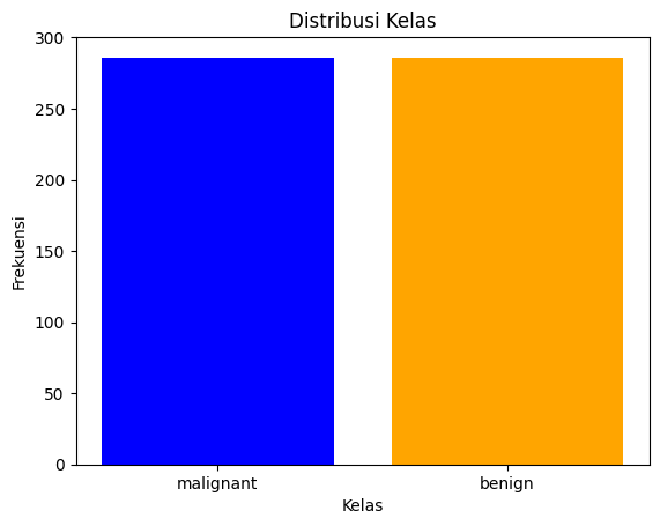
Terlihat bahwa, distribusi kelas menjadi seimbang.
SMOTE adalah alat yang berguna untuk meningkatkan keseimbangan kelas dan menghasilkan model yang lebih baik dalam kasus ketidakseimbangan kelas. Namun, perlu diingat bahwa SMOTE tidak selalu cocok untuk semua kasus, dan perlu dilakukan evaluasi tambahan terhadap dampaknya terhadap kinerja model.
C. Undersampling dengan NearMiss #
1. Mengenal NearMiss #
NearMiss adalah salah satu teknik undersampling yang digunakan untuk menangani ketidakseimbangan kelas dalam dataset. Teknik ini bertujuan untuk mengurangi jumlah sampel dari kelas mayoritas (kelas yang memiliki banyak sampel) sehingga jumlahnya lebih mendekati jumlah sampel dari kelas minoritas (kelas yang memiliki sedikit sampel). Hal ini membantu mengurangi efek ketidakseimbangan kelas pada model machine learning.
2. Prinsip Dasar #
NearMiss bekerja dengan cara mengurangi jumlah data sampel dari kelas mayoritas berdasarkan jarak atau kesamaan antara sampel-sampel tersebut dan sampel-sampel dalam kelas minoritas. NearMiss menggunakan metrik jarak, seperti Euclidean, untuk mengidentifikasi sampel-sampel dari kelas mayoritas yang “dekat” dengan sampel-sampel dari kelas minoritas.
3. Algoritma NearMiss #
Berikut adalah langkah-langkah undersampling menggunakan NearMiss:
- Pilih satu sampel acak dari kelas minoritas.
- Temukan sampel-sampel dari kelas mayoritas yang “dekat” dengan sampel minoritas tersebut berdasarkan kriteria jarak tertentu.
- Hapus sampel-sampel mayoritas yang dipilih, sehingga jumlahnya mendekati jumlah sampel minoritas.
4. Jenis NearMiss #
NearMiss memiliki beberapa jenis, yaitu:
- NearMiss-1: Menghapus sampel-sampel mayoritas yang memiliki jarak minimum ke sampel minoritas.
- NearMiss-2: Menghapus sampel-sampel mayoritas yang memiliki jarak minimum, tetapi juga mempertahankan sampel-sampel yang memiliki jarak minimum di antara sampel mayoritas yang telah dipilih.
- NearMiss-3: Menghapus sampel-sampel mayoritas yang memiliki jarak rata-rata terkecil ke sampel minoritas.
5. Kelebihan dan Kekurangan NearMiss #
Berikut adalah beberapa kelebihan NearMiss:
- Mengatasi ketidakseimbangan kelas dengan mengurangi jumlah sampel mayoritas.
- Meningkatkan interpretabilitas model pada kelas minoritas.
Berikut adalah beberapa kekurangan NearMiss:
- Informasi yang hilang dari sampel mayoritas dapat mempengaruhi kinerja model pada kelas mayoritas.
- Penghapusan sampel-sampel mayoritas dapat menyebabkan hilangnya variasi dan kompleksitas model.
6. Implementasi NearMiss #
NearMiss dapat diimplementasikan dengan menggunakan library seperti scikit-learn di Python (from imblearn.under_sampling import NearMiss).
Berikut adalah contoh penggunaan NearMiss dalam Python dengan scikit-learn:
from imblearn.under_sampling import NearMiss
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# Split dataset menjadi train dan test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Menggunakan NearMiss untuk undersampling
nearmiss = NearMiss(version=1) # Kamu bisa menggunakan versi NearMiss-1, NearMiss-2, atau NearMiss-3
X_resampled, y_resampled = nearmiss.fit_resample(X_train, y_train)
Variabel X_resampled dan y_resampled adalah versi data pelatihan yang telah di-undersampling untuk meningkatkan keseimbangan antara kelas.
NearMiss dapat membantu mengurangi ketidakseimbangan kelas, tetapi perlu diingat bahwa keputusan untuk menggunakan undersampling atau oversampling, serta pilihan teknik undersampling atau oversampling tertentu, harus didasarkan pada karakteristik khusus dari dataset dan tujuan dari model machine learning yang akan dibangun. Evaluasi tambahan juga perlu dilakukan terhadap kinerja model setelah penerapan teknik undersampling atau oversampling.